AI Algorithms You Should Know: A Practical Guide for Developers
Look, I’ll be honest. When I first started messing around with AI, I thought I could just plug in some TensorFlow code and call myself a machine learning engineer. Spoiler: I couldn’t. I spent two weeks trying to figure out why my image classifier kept identifying my cat as a toaster. Turns out, understanding the actual algorithms behind AI isn’t optional if you want to build anything that actually works.
So here’s what I wish someone had told me three years ago: you don’t need to memorize every algorithm ever invented, but you absolutely need to know which ones solve which problems. This article is that conversation I needed. No PhD required.
This article is part of our comprehensive guide on Artificial Intelligence and Machine Learning. For the full roadmap on AI concepts, check out the main guide.
Why Algorithms Actually Matter (Even If You’re Using Libraries)
Here’s the thing. Modern frameworks like scikit-learn and PyTorch make it stupidly easy to implement complex algorithms. You can train a neural network in three lines of code. But when that model starts giving you garbage predictions, you’re going to need to know what’s happening under the hood.
I learned this the hard way when our recommendation system started suggesting winter coats to users in July. The algorithm wasn’t broken. I was just using the wrong one for time-series data.
The Essential Algorithms (That I’ve Actually Used)

1. Linear Regression (Yes, Really)
I know what you’re thinking. “Linear regression? That’s baby stuff.” And you’re right, until you need to predict server load based on user activity and suddenly it’s 2 AM and you’re remembering why simple solutions work.
What it does: Finds relationships between variables and predicts continuous outcomes.
Real use case: I used this to predict our AWS costs based on traffic patterns. Saved us from a surprise $3,000 bill during a traffic spike. The model was basic but it worked.
When it fails: Non-linear relationships. Don’t try to fit a straight line through data that curves. I tried this with user engagement data once and got predictions that were off by 40%.
2. Logistic Regression (For Binary Decisions)
Despite the name, this is for classification, not regression. Confusing, I know.
What it does: Predicts yes/no outcomes. Will this user click? Will this transaction be fraud? Will this email be spam?
Real use case: We built a simple fraud detection system using logistic regression. It caught about 85% of fraudulent transactions with minimal false positives. Not perfect, but good enough for v1.
For more on how AI handles security, check out AI in Cybersecurity.
The gotcha: It assumes your features are independent. Ours weren’t. Spent a week figuring out why our model was overconfident before realizing we had correlated features messing things up.
3. Decision Trees and Random Forests
Decision trees are like flowcharts on steroids. Random forests are what happens when you make a bunch of decision trees vote on the answer.
What it does: Makes decisions by asking a series of yes/no questions about your data.
Real use case: Used random forests for customer churn prediction. The model was interpretable, which made our product team actually trust it. That matters more than people think.
Why I like it: You can visualize what it’s doing. When your boss asks “why did the model decide that?” you can actually explain it.
The catch: They overfit like crazy if you’re not careful. I trained a model that was 98% accurate on training data and 60% accurate on real data. Classic rookie mistake.
4. K-Nearest Neighbors (KNN)
This one’s almost too simple. It literally just looks at the K closest examples to your data point and takes a vote.
What it does: Classifies things based on what their neighbors look like.
Real use case: Built a product recommendation system with KNN. “Users who liked this also liked…” type stuff. Worked surprisingly well for a prototype.
Why it’s annoying: Gets slower as your dataset grows. We had to switch to approximate KNN when we hit 100k users because queries were taking 3 seconds. Not great for a real-time system.
If you’re building recommendation engines, you’ll want to read about AI in E-Commerce for more context.
5. Support Vector Machines (SVM)
SVMs try to find the best boundary between different classes in your data. Think of it like drawing the perfect line to separate cats from dogs in a photo.
What it does: Creates decision boundaries in high-dimensional spaces.
Real use case: Text classification. We used SVMs to categorize support tickets. Worked better than I expected for a dataset with 50+ categories.
The pain point: Choosing the right kernel is part art, part science. I spent two days tuning parameters before realizing the linear kernel worked fine. Sometimes simple wins.
6. Neural Networks (The Overhyped But Useful One)
Everyone talks about neural networks like they’re magic. They’re not. They’re just really good at finding patterns in massive amounts of data.
What it does: Layers of connected nodes that learn representations of your data.
Real use case: Image classification for a quality control system. Detecting defects in product photos. This actually needed deep learning because traditional CV methods weren’t cutting it.
For a deeper dive, check out Deep Learning Explained.
Reality check: You need a LOT of data. We tried training a model with 5,000 images and it was garbage. Bumped it to 50,000 and suddenly it worked. Data quality matters more than algorithm choice here.
7. Gradient Boosting (XGBoost, LightGBM)
This is what wins Kaggle competitions. It’s basically “let’s train a bunch of weak models and combine them into something powerful.”
What it does: Builds models sequentially, each one fixing the mistakes of the previous one.
Real use case: Predictive maintenance for IoT sensors. XGBoost crushed it. Beat our neural network by 15% accuracy with 1/10th the training time.
The learning curve: Configuration is a nightmare. Learning rate, max depth, number of estimators… there are like 50 parameters. I still use default settings half the time and just tune the obvious ones.
How to Actually Choose the Right Algorithm
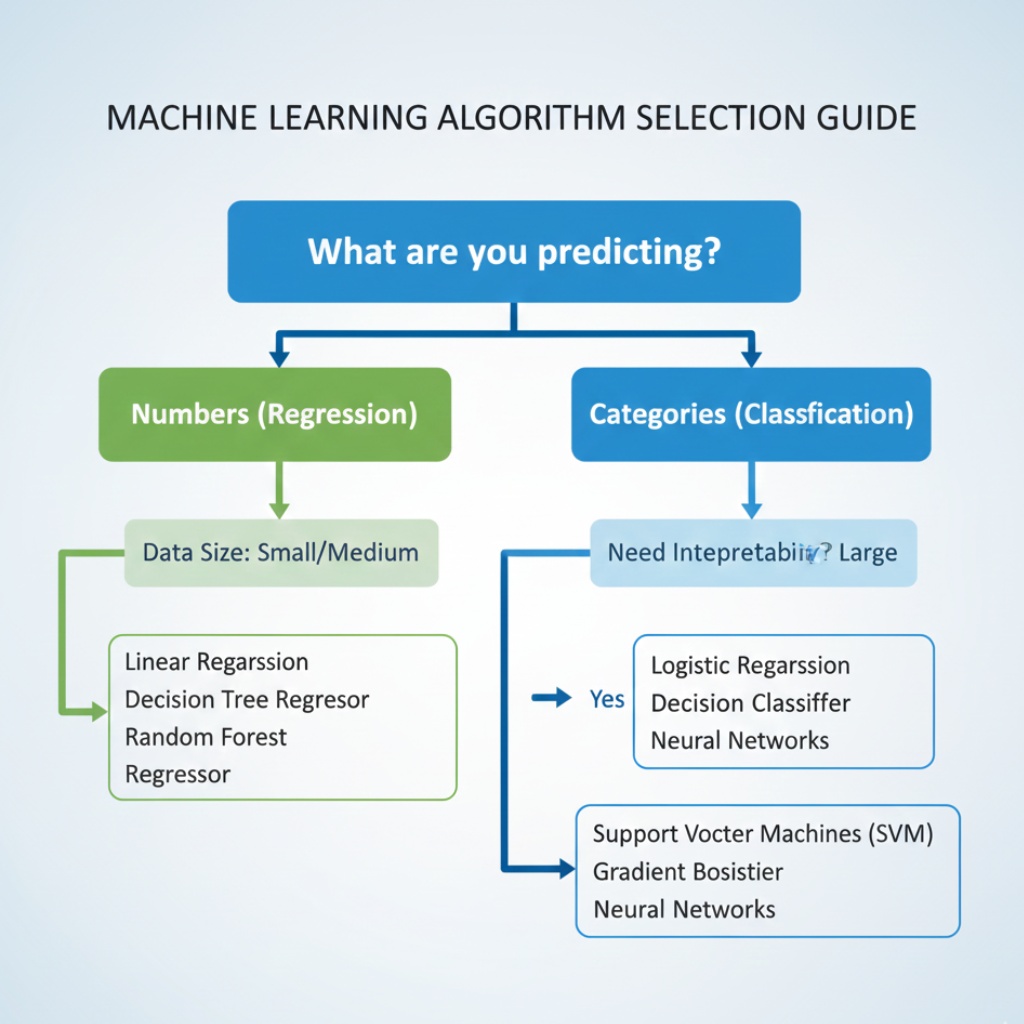
Here’s my decision tree (see what I did there?):
Start simple. I always try logistic regression or a decision tree first. If they work, great. If they don’t, then I’ll move to the complex stuff.
Match the problem type:
- Predicting numbers? Regression algorithms
- Predicting categories? Classification algorithms
- Finding patterns? Clustering algorithms
- Making sequences of decisions? Reinforcement learning
Consider your constraints:
- Need it to be fast? KNN and neural networks are out
- Need to explain predictions? Decision trees and linear models win
- Have tons of data? Deep learning might be worth it
- Need it running yesterday? Use what you know best
For understanding different types of AI approaches, visit Types of Artificial Intelligence.
Common Mistakes I’ve Made (So You Don’t Have To)

Using deep learning for small datasets. I wasted a month building a CNN for a classification problem with 2,000 samples. A random forest would’ve worked fine and taken two hours.
Not normalizing features. Your algorithm doesn’t know that “age” ranges from 0-100 and “income” ranges from 0-1,000,000. Scale your features. I’ve debugged this problem at least five times.
Ignoring the baseline. Always check what a dumb model would do. If 90% of your data is class A, a model that just predicts A gets 90% accuracy. Don’t celebrate until you beat the baseline.
Overfitting on training data. Split your data. Use cross-validation. I’ve shipped models that worked great in development and sucked in production because I didn’t validate properly.
Tools and Libraries That Actually Help
I’m not going to list every library that exists. Here’s what I actually use:
scikit-learn: Start here. It’s got everything and the docs are solid.
XGBoost/LightGBM: When you need better performance than scikit-learn’s gradient boosting.
TensorFlow/PyTorch: When you actually need deep learning (which is less often than you think).
For getting started with these tools, check out AI Tools for Beginners.
The best tool? Whatever you can actually ship. I’ve seen elegant TensorFlow models that never made it to production and janky logistic regressions that ran for years making money.
What to Learn Next
If you’re serious about AI algorithms, here’s my suggested path:
- Get comfortable with one algorithm at a time. Actually implement it, break it, fix it.
- Learn when each algorithm fails. That’s more valuable than knowing when they work.
- Focus on feature engineering. Seriously. Good features with a simple algorithm beats great algorithms with bad features every time.
- Study evaluation metrics. Accuracy isn’t everything. Learn precision, recall, F1, ROC curves, and when to use each.
For more on the fundamentals, check out Machine Learning Basics and our guide on AI Programming Languages.
The Real Talk
Look, algorithms are tools. You don’t need to know every screwdriver in existence to build furniture. But you should know the difference between a Phillips and a flathead.
Start with the basics. Linear regression, logistic regression, decision trees. Get really good at those. Then expand to the fancier stuff when you actually need it.
And please, for the love of all that is holy, don’t use neural networks because they sound cool. Use them because they’re the right tool for your specific problem. Your future self (and your production environment) will thank you.
Want to see these algorithms in action? Check out AI Case Studies for real-world implementations, or explore Challenges in AI Development to understand common pitfalls.
Ready to dive deeper? Head back to our main AI and Machine Learning guide for more comprehensive coverage of AI topics.