Deep Learning Explained: What Neural Networks Actually Do (And Why Everyone’s Obsessed)
Look, I’ve been writing about tech for five years now, and I can’t tell you how many times someone’s asked me to explain deep learning. Usually right after they’ve seen some article about AI beating humans at chess or generating art.
Here’s the thing: deep learning sounds complicated. And yeah, the math behind it can get intense. But the core concept? That’s actually pretty straightforward once you get past all the buzzwords.
Let me break it down the way I wish someone had explained it to me back in 2019.
What Deep Learning Actually Is
Deep learning is a subset of machine learning that uses neural networks with multiple layers. That’s it. That’s the definition.
But what does that mean in practice?
Think of it like this: you know how a kid learns to recognize a dog? They see a bunch of dogs, their brain picks up on patterns (four legs, fur, tail, makes barking sounds), and eventually they can spot a dog even if they’ve never seen that specific breed before.
Deep learning tries to replicate that. Not perfectly, obviously. But well enough that it’s kind of freaky sometimes.
I remember the first time I built a simple image classifier. Fed it 10,000 pictures of cats and dogs, and after a few hours of training, it could tell them apart with 95% accuracy. I was both impressed and slightly worried about what else it could figure out.

The Neural Network Part Everyone Gets Wrong
So neural networks. The name makes people think we’re talking about actual brain cells. We’re not. It’s inspired by biology, sure, but it’s really just math.
Here’s what’s actually happening:
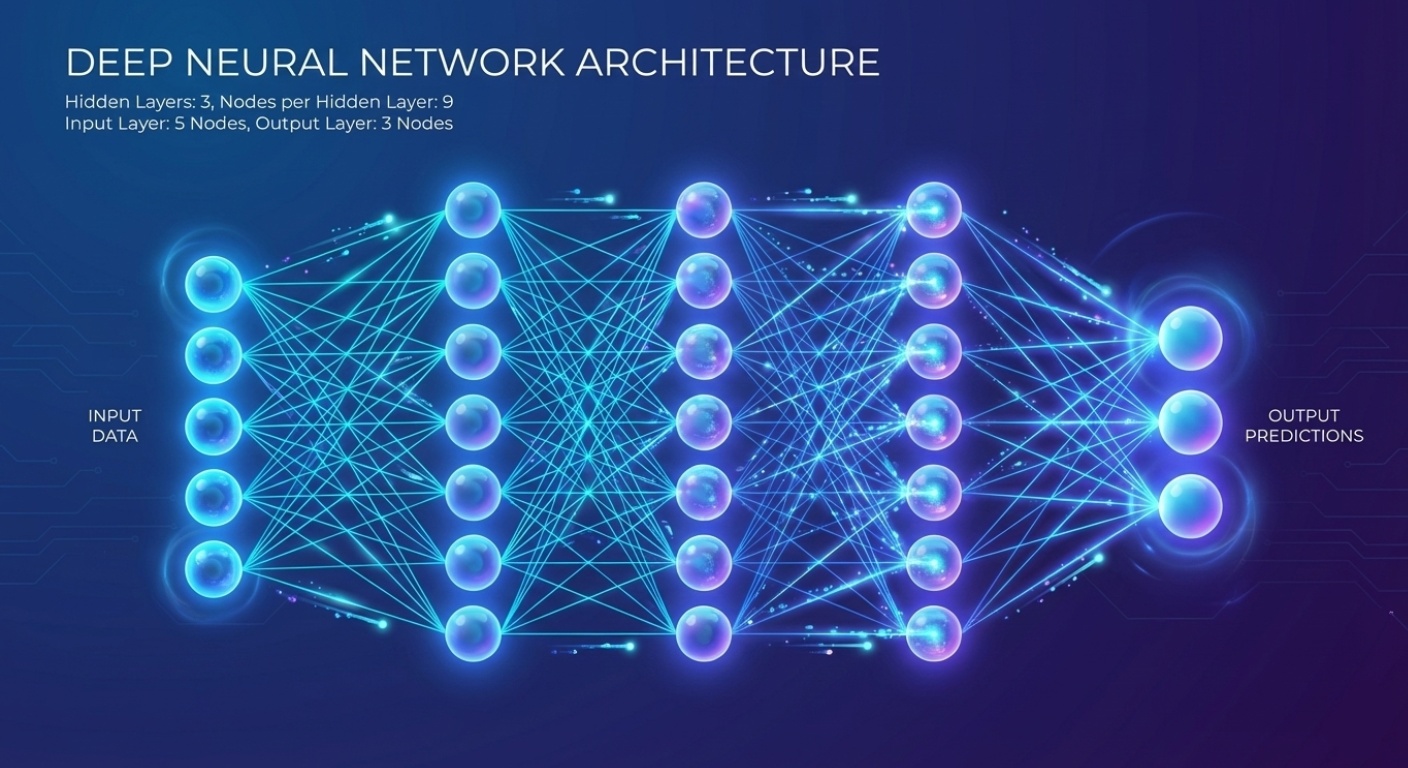
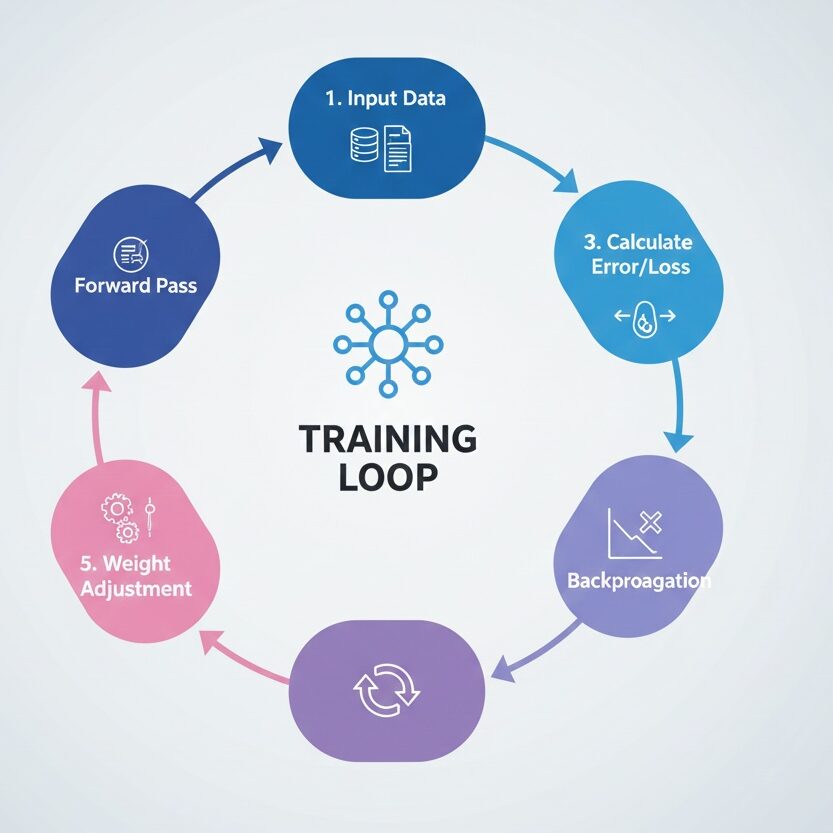
A neural network is a bunch of interconnected nodes (we call them neurons, which doesn’t help the confusion). Each connection has a weight. When data flows through, these weights determine how much influence one node has on another.
You start with random weights. The network makes terrible predictions. Then you adjust the weights based on how wrong it was. You do this thousands or millions of times until it gets good at whatever task you’re training it for.
The “deep” in deep learning just means there are multiple layers between the input and output. More layers means the network can learn more complex patterns. It also means longer training times and more data needed, but that’s a tradeoff we deal with.

Why Deep Learning Took Off (Spoiler: It’s Not Just the Algorithms)
Deep learning isn’t new. The concepts have been around since the 1980s. But three things changed in the last decade:
Computing power got cheap. GPUs, which were originally built for gaming, turned out to be perfect for the parallel processing neural networks need. I’ve got more computing power on my desk now than entire research labs had in 2010.
Data became abundant. Deep learning is hungry. It needs tons of examples to learn from. The internet gave us that. Every photo you upload, every click you make – that’s all potential training data.
Better algorithms showed up. Researchers figured out tricks to make training more efficient. Things like ReLU activation functions, dropout layers, batch normalization. Don’t worry about the terms, just know they made everything work better.
I watched this transformation happen in real time. In 2018, training a decent model could take weeks. Now? Sometimes it’s done over lunch.
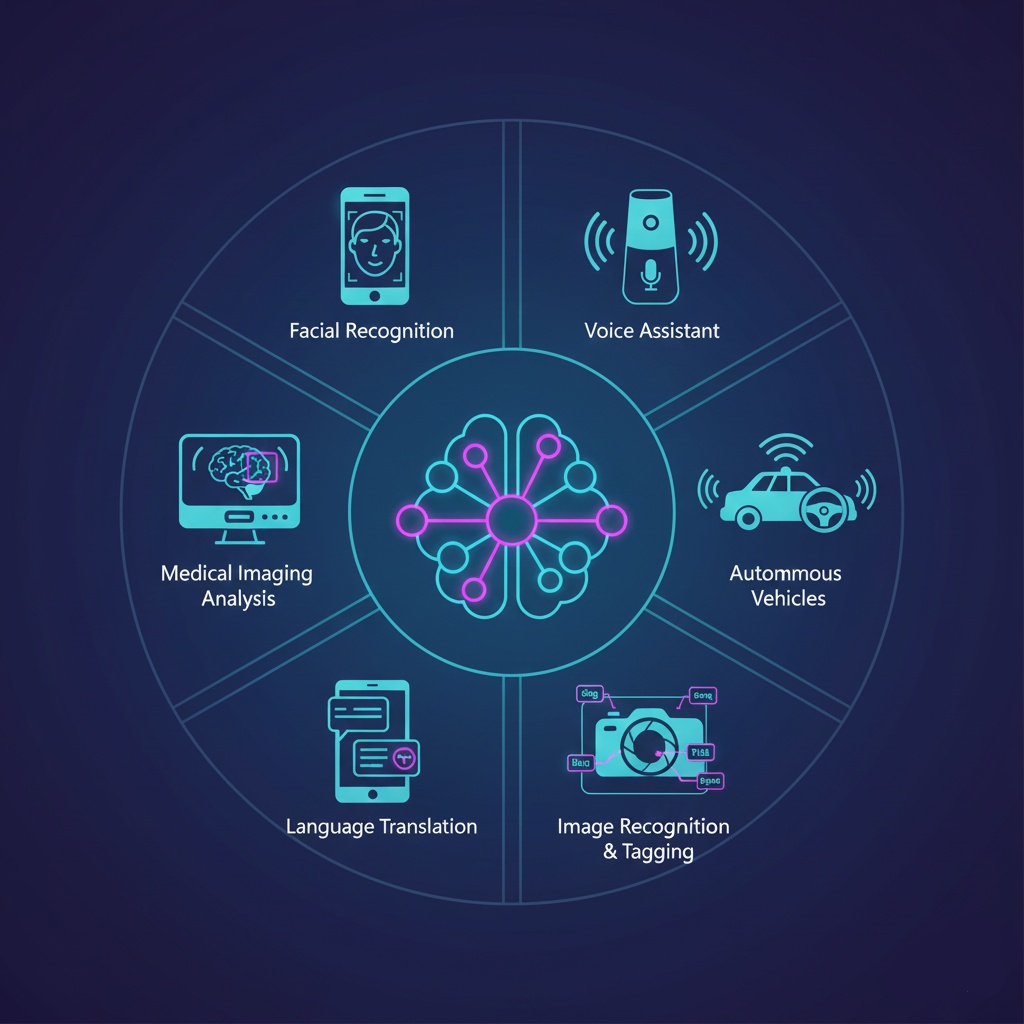
What Deep Learning Is Actually Good At
This is where it gets practical. Deep learning excels at pattern recognition tasks that would be nightmare to program manually.
Image recognition is the obvious one. Show a neural network enough pictures of cats, and it’ll learn what “catness” looks like. This powers everything from facial recognition to medical imaging. When your phone suggests tagging your friends in photos? Deep learning.
Natural language processing is another big one. Understanding human language is messy. Context matters, sarcasm exists, and we make up new slang constantly. Deep learning handles this ambiguity way better than rule-based systems ever could. Natural language processing has come a long way because of it.
Speech recognition works now. Like, actually works. Remember when voice assistants were basically useless? Deep learning fixed that. The models can handle accents, background noise, and even that weird way your uncle mumbles.
Playing games turns out to be something deep learning is weirdly good at. Not because games matter that much, but because they’re good testing grounds. AlphaGo beating the world champion at Go? That was deep learning proving it could handle strategy and intuition.
The Parts Nobody Talks About (Until You’re Three Months Into a Project)
Okay, real talk. Deep learning isn’t magic. It’s powerful, but it has serious limitations.
Data quality matters more than you think. I learned this the hard way on a client project. We had 50,000 training examples, felt great about it. Then we discovered about 30% were mislabeled. The model learned garbage and our accuracy was terrible. Took two weeks to clean up the data.
Black box problem is real. Sometimes a neural network makes a decision and you have no idea why. It’s not like traditional code where you can trace the logic. This is a huge issue in healthcare and finance where you need to explain decisions.
Training is expensive. Not just computationally, but in time and money. GPT-3 cost an estimated $4.6 million to train. Even smaller models can rack up cloud computing bills fast. I’ve seen startups burn through their runway on training costs.
Overfitting happens constantly. Your model performs great on training data, then falls apart on real-world examples. It memorized instead of learning. You’ll spend a lot of time tuning hyperparameters to prevent this.
How Deep Learning Fits Into Broader AI
Deep learning gets a lot of hype, but it’s just one piece of the artificial intelligence puzzle.
You’ve got traditional machine learning algorithms that work great for structured data. You’ve got reinforcement learning for decision-making tasks. You’ve got good old-fashioned programming for rule-based logic.
The best AI systems usually combine multiple approaches. Deep learning might handle the pattern recognition, but you still need other tools for reasoning, planning, and actually making sense of what the model outputs.
I’ve worked on projects where we spent weeks building a deep learning model, then realized a simple decision tree would’ve solved the problem better. Sometimes the fancy tool isn’t the right tool.
Common Deep Learning Architectures You’ll Run Into
If you start playing with deep learning, you’ll see these terms everywhere:
Convolutional Neural Networks (CNNs) are for image data. They’re designed to recognize visual patterns in a way that doesn’t care about exact position. That’s why they work so well for photos.
Recurrent Neural Networks (RNNs) handle sequential data. Text, time series, anything where order matters. They have memory of previous inputs, which makes them good for language tasks.
Transformers are the new hotness. They power models like GPT and BERT. Better at handling long-range dependencies than RNNs, and they parallelize better so training is faster.
Generative Adversarial Networks (GANs) are where you have two networks competing. One generates fake data, the other tries to spot the fakes. This competition makes both better. Generative AI owes a lot to GANs.
Getting Started Without Losing Your Mind
If you want to actually try deep learning, start small. Don’t try to build GPT-5 in your basement.
Pick a simple problem. Maybe classify images into a few categories. Use existing frameworks like TensorFlow or PyTorch – no need to implement everything from scratch. There are AI tools for beginners that make this way easier than it used to be.
Get comfortable with the basics before you worry about the cutting edge research. Understanding how a simple feedforward network works will teach you more than reading papers about the latest architecture.
And seriously, start with small datasets. You can learn everything you need with a few thousand examples. Don’t fall into the trap of thinking you need millions of data points to get started.
The Bottom Line
Deep learning is powerful. It’s transformed how we approach problems that involve pattern recognition. But it’s not artificial general intelligence, it’s not going to solve every problem, and it comes with real tradeoffs.
I’ve seen projects fail because teams threw deep learning at problems that didn’t need it. I’ve also seen it produce results that seemed impossible five years ago.
The key is understanding what it’s actually good at, what the limitations are, and whether it’s the right tool for your specific problem. Sometimes it is. Sometimes it’s overkill.
But if you’re building anything that involves images, text, or speech? Yeah, you probably want to at least consider it. Just go in with realistic expectations and a willingness to debug some frustratingly opaque errors.
This article is part of our comprehensive guide on Artificial Intelligence and Machine Learning. For more on AI fundamentals and applications, check out the full guide.