Reinforcement Learning Explained: What Nobody Tells You About Teaching Machines Through Trial and Error
This article is part of our comprehensive guide on Artificial Intelligence (AI) and Machine Learning. For the complete guide covering all AI fundamentals, visit the main resource.
Look, I’m going to level with you. When I first tried to understand reinforcement learning, I spent two weeks reading papers that made my brain hurt. Every explanation started with “imagine you’re training a dog” or showed some robot learning to walk. Cool visuals, but they didn’t help me actually build anything.
Here’s what I wish someone had told me upfront: reinforcement learning is just trial and error with math. That’s it. An agent does something, gets feedback (good or bad), and adjusts. Repeat a million times until it stops being terrible.
What Actually Is Reinforcement Learning?
Remember playing video games as a kid? You died a bunch, learned which jumps were possible, and eventually beat the level. That’s reinforcement learning.
In machine learning terms, we’ve got:
- An agent (the thing learning)
- An environment (the world it’s operating in)
- Actions (what it can do)
- Rewards (feedback on whether that action was smart)
- A policy (its strategy for picking actions)
The agent tries actions, gets rewards (or penalties), and slowly figures out which moves lead to good outcomes. No labeled training data needed like in traditional machine learning. The agent learns by doing.
Why This Matters (And Why I Care)
I got into RL when we tried to optimize ad bidding at my last job. We had historical data, sure, but the market changed every hour. Traditional models couldn’t keep up.
Reinforcement learning was different. It could adjust its bidding strategy based on real-time feedback. Did we win the auction? Good reward. Did we overpay? Negative reward. Over a few weeks, it learned bidding patterns that our data scientists never would’ve coded manually.
That’s the power here. RL handles situations where the rules aren’t clear and the environment keeps changing.
The Core Loop: How Agents Learn
Every RL system follows the same pattern:
- Agent observes current state
- Agent picks an action based on its policy
- Environment responds with new state and reward
- Agent updates its policy
- Repeat until it stops sucking
Sounds simple, right? It is. The complexity is in step 4, figuring out how to update that policy.
Exploration vs. Exploitation
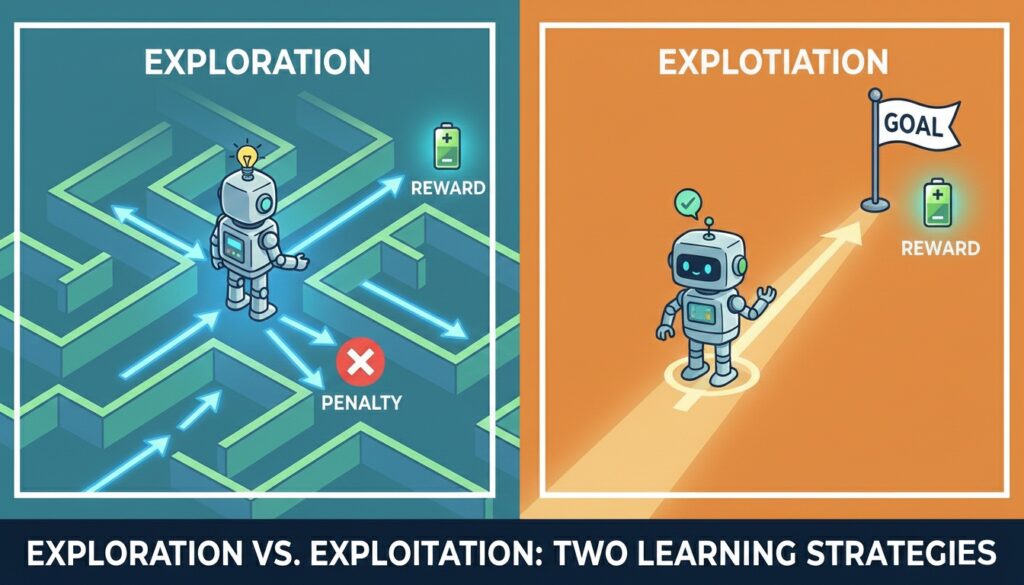
Here’s where it gets interesting. Should your agent try new things (exploration) or stick with what’s worked before (exploitation)?
Try only what works? You’ll never discover better strategies. Always try new things? You’ll never capitalize on what you’ve learned.
This tradeoff bit me hard when we trained a chatbot for customer support. Early on, it needed to explore different response types. But in production? We wanted it to exploit its best responses, not experiment on customers.
We solved it with epsilon-greedy strategy. The agent explores 10% of the time, exploits 90%. As it got smarter, we dropped exploration to 5%. Not perfect, but way better than our first attempt where it kept trying weird responses on actual users.
Types of RL You’ll Actually Use
There are dozens of RL algorithms. Most of them you’ll never touch. Here are the ones that matter:
Q-Learning
This is where most people start. The agent builds a Q-table (quality table) that stores expected rewards for each state-action pair.
I used Q-learning to train a bot for a simple grid-based game. Worked great because the state space was small. 100 grid positions, 4 possible moves per position. Easy to store in a table.
But scale that up? Forget it. Once you’ve got millions of states, Q-tables become impossible.
Deep Q-Networks (DQN)
This is Q-learning but using a neural network instead of a table. It’s what DeepMind used to train an AI to play Atari games better than humans.
The neural network learns to approximate Q-values for any state, even ones it’s never seen. This is huge for complex environments.
I tried implementing DQN for a trading bot last year. Results were… mixed. It learned some patterns, but training took forever (72 hours on a decent GPU), and it still made bizarre decisions sometimes. Turns out financial markets are way harder than Pong.
If you want to understand the neural network side better, check out our guide on deep learning.
Policy Gradient Methods
Instead of learning Q-values, these methods directly learn the best policy (the strategy itself). They’re better for continuous action spaces.
Think robot arms. You don’t want discrete actions like “move left” or “move right.” You want smooth, continuous control. Policy gradients handle this well.
Actor-Critic
This combines value-based methods (Q-learning) with policy-based methods. You get an actor (decides actions) and a critic (evaluates those actions). They work together, each making the other smarter.
It’s more complex to implement, but it’s stable and efficient. Big companies use variations of actor-critic for production systems.
Real-World Applications (Beyond the Usual Examples)
Everyone talks about AlphaGo and robotics. Let me tell you about less flashy but actually useful applications:
Dynamic Pricing Airlines and hotels use RL to adjust prices in real-time. The agent learns which price points maximize revenue based on demand, competition, and booking patterns.
Resource Allocation Data centers use RL to manage server loads. When should you spin up new instances? When should you consolidate? An RL agent can optimize this better than fixed rules.
Recommendation Systems Netflix and Spotify don’t just use collaborative filtering. They use RL to learn long-term user engagement. Should they recommend that niche documentary now or save it for later? The agent figures it out.
Game AI Not just learning to play games, but creating smarter NPCs. Check out our post on AI in gaming for more on this.
The Problems Nobody Warns You About
Training Takes Forever
I’m not kidding. Training a decent RL agent can take days or weeks. My trading bot? 72 hours. And that was for a simplified simulation.
The agent needs to try millions of actions to learn anything useful. There’s no shortcut. You need patience and good hardware.
Reward Design Is Hell
This is the hardest part. What rewards do you give? When? How much?
Get this wrong and your agent learns the wrong thing entirely. I once trained a bot to navigate a maze. I gave it a reward for getting closer to the goal. Seems logical, right?
The bot learned to get near the goal and then just vibrate there, collecting small distance rewards forever. Never actually finished the maze.
Reward shaping is an art, not a science. You’ll mess it up the first few times. Everyone does.
It’s Sample Inefficient
RL agents need tons of examples to learn basic tasks. A human can learn a new game in minutes. An RL agent might need thousands of episodes.
This makes RL impractical for situations where you can’t generate lots of training data cheaply. Real-world robotics? Expensive. Can’t just let a $50k robot arm crash into things a million times.
Simulation helps, but there’s always a sim-to-real gap. What works in simulation doesn’t always transfer to the real world.
Getting Started: My Honest Advice
Don’t start with the math papers. I did that. It sucked.
Start with OpenAI Gym. It’s a toolkit with pre-built environments (simple games, physics simulations, etc.). You can test RL algorithms without building your own environment from scratch.
Install it:
pip install gym
Try training an agent on CartPole (balancing a pole on a cart). It’s simple enough to train in minutes, complex enough to teach you the basics.
For AI algorithms and implementation details, we’ve got a dedicated guide that goes deeper into the code side.
Once you’ve got CartPole working, try a slightly harder environment. Then another. By your fifth project, you’ll start to intuitively understand what works and what doesn’t.
Should You Actually Use RL?
Real talk: most problems don’t need reinforcement learning.
Got labeled data? Use supervised learning. It’s easier and faster. Got clear rules? Use traditional programming. It’s more reliable.
Use RL when:
- The environment is dynamic and changes over time
- You can generate lots of training examples (real or simulated)
- The optimal strategy isn’t obvious
- You need the system to adapt continuously
Otherwise? You’re making your life harder for no reason.
Where RL Is Heading
The field’s moving fast. A few trends I’m watching:
Model-Based RL: Instead of learning through pure trial and error, the agent builds a model of the environment. This makes learning way more efficient.
Multi-Agent RL: Multiple agents learning together (or competing). Think autonomous cars coordinating at intersections.
Offline RL: Training agents on fixed datasets instead of live interaction. This is huge for real-world applications where live trial and error is expensive or dangerous.
For more on where AI research is going, check out AI research papers and trends.
Final Thoughts
Reinforcement learning isn’t magic. It’s a tool. A powerful one, but with real limitations.
I’ve seen it work brilliantly (optimizing ad spend, game AI, dynamic pricing). I’ve also seen it fail spectacularly (my trading bot, a failed chatbot experiment, and that maze-vibrating disaster).
The key is knowing when to use it and having realistic expectations. If you’ve got the patience to train agents and the resources to let them learn through trial and error, RL opens up possibilities that other ML approaches can’t touch.
Just don’t expect it to be easy. And definitely don’t expect your first agent to work. Mine didn’t. Neither will yours.
But when it finally clicks and you watch your agent figure out something you never explicitly taught it? That’s genuinely cool.
Want to explore more AI concepts? Head back to our complete AI and machine learning guide or dive into related topics like predictive analytics and AI tools for beginners.